When Sample Selection Bias Precipitates Model Collapseedit
ICML 2026 paper on low-resource verification regimes, sample-selection bias, model collapse, and collaborative Wasserstein-geometry proxies.
When Sample Selection Bias Precipitates Model Collapse is an ICML 2026 conference paper by Xinbao Qiao, Xianglong Du, Wei Liu, Jingqi Zhang, Peihua Mai, Meng Zhang, and Yan Pang. It studies a failure mode in recursive synthetic-data training: a verifier with only local, low-resource evidence can mistake rare but valid samples for low-quality generations, causing sample selection to amplify model collapse rather than prevent it. The paper frames collaborative Wasserstein-geometry proxies as a way to evaluate synthetic samples against a broader distributional reference without pooling raw data.

Overviewedit
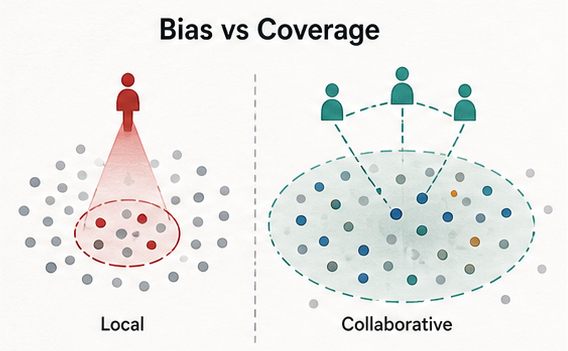
The paper studies model collapse in recursive synthetic-data training. Prior work often treats data selection as a stabilizing tool: a verifier filters generated samples so that only high-quality synthetic data are reused for training. This paper makes the verifier itself the object of analysis. When the verifier sees only a small, fragmented, and biased slice of the target distribution, selection can repeatedly reward samples near that local slice and remove globally relevant tail modes that future generators need.
The motivating setting is a low-resource data-silo environment. A hospital consortium, bank, or proprietary institution may evaluate synthetic samples against its own limited reference data because raw data cannot be pooled. Selection then becomes a confirmation-bias mechanism: samples close to the local view are retained, while rare but valid modes are pruned away. The updated framing emphasizes why low-resource communities are especially vulnerable: tail regions are already weakly represented before synthetic augmentation begins, so local filtering can turn scarcity into persistent coverage loss.
Methodedit
The paper first formalizes biased top-alpha selection under Gaussian modeling and connects it to variance collapse across recursive generations. It then proposes collaborative evaluation methods that replace a single local verifier with distributional proxies computed across parties without raw-data exchange. The methodological shift is from sample quality as judged by one low-resource silo to distributional fit against a proxy for the global target.
Two schemes are described:
- Scheme I, collaborative geodesic interpolation, constructs proxy measures along Wasserstein geodesics between synthetic and local real distributions;
- Scheme II, collaborative Wasserstein barycenter estimation, computes a reusable barycenter proxy for the collective reference distribution.
Both schemes use Wasserstein-gradient-based sample scoring, so the synthetic pool is evaluated against a multi-party distributional reference rather than one biased silo.
Key formulaedit
The paper's theory links local selection, diversity decay, and Wasserstein cost. In the following summary, is the selected top- region, is the filtered synthetic distribution at generation , and is the target distribution.
Local verifier selection is summarized as truncated sampling:
The resulting diversity decay can be expressed through the covariance trace:
A Wasserstein generalization bound then relates model risk under the target distribution to the filtered distribution:
The collaborative scoring rule can be viewed through a dual potential :
The formulas explain the paper's main mechanism: biased selection can make the retained distribution increasingly narrow, while collaborative Wasserstein proxies try to reduce the discrepancy between filtered synthetic data and the global target distribution.
Resultsedit
The manuscript reports DDPM-style recursive image-generation experiments on CIFAR-10, STL-10, and CelebA. Baselines include Random selection, K-means, CenterMatch, and CovMatch. Under non-IID or locally skewed references, local-selection baselines can fall behind random selection, while the collaborative schemes better preserve both sample quality and mode coverage.
The main lesson is that low-resource regimes are not merely smaller versions of high-resource settings. When real-data coverage is scarce or fragmented, tail modes may already be difficult to observe. Local-reference selection can then confuse rare but valid samples with low-quality generations, systematically suppressing underrepresented regions of the target distribution. An appendix experiment with a topic-local LLM verifier makes the same point semantically: filtering against a narrow local topic can reduce held-out topic coverage rather than protect it.
Placementedit
This work belongs to Synthetic Data, Synthetic Data, Recursive Synthetic Data Training, Data Selection, Sample Selection Bias, Data Silos, Collaborative Evaluation, and Wasserstein Geometry. It is the synthetic-data counterpart to Qiao's unlearning papers: instead of asking how to remove data after training, it asks how selection and verification shape the data stream before future training. The low-resource emphasis also connects the paper to the social side of model collapse: distributional tail loss can correspond to the loss of culturally, linguistically, or institutionally underrepresented content.