DynFrs:随机森林机器遗忘高效框架edit
ICLR 2025 论文,研究随机森林中的高效机器遗忘。
DynFrs:随机森林机器遗忘高效框架 是 Shurong Wang、Zhuoyang Shen、乔鑫宝、Tongning Zhang 和张萌的 ICLR 2025 会议论文。该工作把随机森林遗忘视为动态数据结构问题:在保持与重新训练分布等价的同时,降低在线删除、插入和查询延迟。

概述edit
论文研究 随机森林 的精确高效 机器遗忘。随机森林仍广泛用于医疗、金融和推荐等隐私敏感领域,但树集成结构使标准梯度式遗忘工具难以适用。
DynFrs 面向森林的三类在线操作:预测、样本删除和样本添加。其核心设计目标是在保持精确遗忘所需分布等价性的同时,降低在线修改延迟。因此论文把遗忘视为数据结构与随机算法问题,而不只是模型更新问题。
方法edit
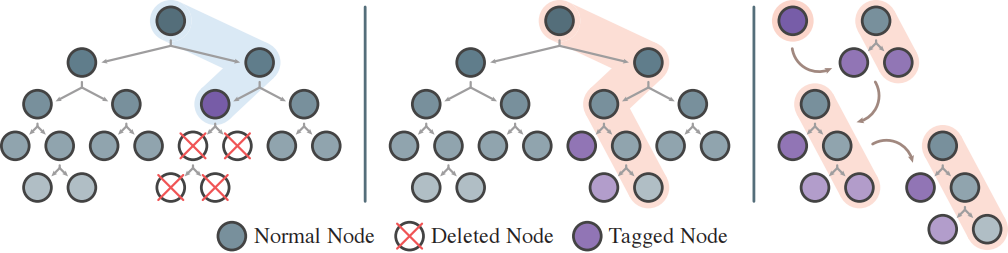
DynFrs 结合三种机制:
- OCC(q):树子采样规则,使每个训练样本只出现在 棵树中的 棵;
- LZY:lazy-tag 机制,将子树重建推迟到后续查询真正经过受影响路径时;
- ERT:使用 Extremely Randomized Tree 作为基学习器,使随机划分候选降低结构对局部样本变化的敏感性。
关键公式edit
设 为森林规模, 为出现因子,。OCC 规则限制每个样本进入的树数:
训练时间尺度为:
OCC() 带来的期望遗忘加速可概括为:
精确遗忘要求遗忘算法与不含被删样本的重新训练在分布上等价:
lazy-tag 机制把可能很大的子树重建,转化为未来查询抵达标记节点时的路径级重建。
结果edit
OpenReview 论文报告 DynFrs 相比已有随机森林遗忘方法实现数量级加速,同时保持或提高预测准确率。论文 PDF 报告相对朴素重新训练有 4000 到 1,500,000 倍加速,相对 DaRE 在顺序遗忘中有 22 到 523 倍加速;在大规模数据集的混合在线流中,修改请求延迟约为 0.12 ms,查询请求约为 1.3 ms。
实验还区分顺序遗忘与批量遗忘。DynFrs 能在两种设置中保持强表现,是因为 OCC(q) 降低每个样本覆盖的树数,而 LZY 避免每次删除都触发完整子树重建。
定位edit
该工作属于 机器遗忘、随机森林 和 可信 AI。在乔鑫宝的论文记录中,它与 无 Hessian 在线认证遗忘 互补:前者关注树集成的精确遗忘,后者关注可微模型的近似认证遗忘。